This post is part of a series about the challenges behind database performance and how to accurately assess it.
Purpose of an ingress benchmark
When evaluating a timeseries database management system (later referred as TSDBMS or TSDB), one important dimension is the ingress speed (a.k.a. insertion or ingestion), that is, how fast the database can store new data points.
Some use cases have terabytes of data generated per day and it’s unrealistic to hope to be able to support them without excellent ingress speed. Even for less intensive use case, you want to make sure your TSDB can ingest the data at low latency for improved analytics relevance.
It can be measured in points per second (one point being a timestamp, value couple), rows, or bytes per second.
In this article we’ll show you how we benchmark the ingress speed of QuasarDB and how it fares compared to some known competitors.
Considerations for an ingress test
- Nature
- Integers, floats, strings, binary…
- This affects the size of the ingested data, memory allocation, and potentially compression
- Source
- Real world data, generated data, if generated, what kind of generator
- Real is interesting when it’s close to your use case, generated can be useful to test extreme scenario
- Distribution
- Random, constant, normal…
- The distribution of the data will greatly impact compression algorithms, and in the most extreme use case (for example constant data), you will end up with super-efficient compression which may give unrealistic performance numbers.
- Insertion method
- Batch, point by point, query, API…
- Each TSDB provides their users with different methods. You want to select a method that is not at the disadvantage of the TSDB while remaining realistic in its usage. When comparing TSDB between them, you need to make sure the parameters are close enough to make sure you are doing an apple to apple comparison.
- Insertion reliability
- The level of guarantee offered by the database
- Not all TSDB offer strong guarantees regarding insertion, and it can make a big difference! For example, if the database takes ingress through UDP packets, data loss increases significantly as traffic increases. You thus need to test after the ingress that all the data is properly inserted.
Choosing an ingress method
The most two frequent ways we see our customer insert their data into QuasarDB are:
- Ingesting data from files (usually CSV files). The customer has a batch where CSV files are parsed and imported into the database.
- Connecting a stream directly into the database through low level APIs. For example, the customer will connect the stream coming from a stock exchange with our high-performance insertion API.
Our experience for timeseries is, that insertions through SQL queries are limited to corrections and small modifications.
In this post, we’ll explore inserting data from a file as most TSDB have a method for that, giving everyone a fair chance, and it represents a frequent use case.
Designing an ingress benchmark
Data file
For this blog post, we’ll use a 110 MiB file consisting of years of minutes bars (Open, High, Low, Close, Volume) from a Dow Jones stock.
This file is made of floating-point values and integer values and has enough variability so that naive compression will insufficient but not random to the point that compression is impossible.
Each database will ingest the same file.
We will in future posts post more results with different files. It is our experience this 110 MiB file gives a good chance to any database to perform well and a good preview of the performance level a database can deliver.
Ingest method
For each evaluated TSDB, we’re using, if there is an available tool to import data from a file. We’re also considering in the documentation, what kind of guarantee this tool has. If no tool is available, we’ll use the recommended performing API to insert a CSV file.
What and how to measure
For ingestion, you typically want to measure insertion speed and the total disk size. However, there is a catch for both
- For ingestion speed you want to make sure you measure the time when the data is stored in the database, not just when the insertion tool tells you the data has been sent.
- For total disk size, you want to measure post compaction and trimming, if any. This is to give a fair chance to database based on LSM trees and to make sure we don’t count the data twice if there is a write ahead log.
In all rigor you may want to consider the compaction time in the insertion benchmark, however, compaction is amortized across all insertions thus, we decided to measure only when the data is stored in the database (QuasarDB persistence layer uses Helium, which isn’t a LSM).
Test procedure
For each test we’ve done the following, to reduce noise:
- Ensure the TSDB has no activity
- Flush system and TSDB caches, if any
- Insertion is done remotely, that is, the file is read from a machine, sent via the tooling over the network, and inserted into the TSDB instance, on another machine. Remote ingestion is the most frequent scenario.
- Once the insertion is done, run a trimming/vacuum process on the database, if any, and then measure disk usage. This process isn’t included in the insertion time.
Test configuration
The client and the server are linked directly, reducing to almost zero network interference.
Both machines are identical and have the following configuration:
- OS: Ubuntu Server 18.04.2 LTS
- CPU: Intel® Xeon® CPU E5-2609 v4 @ 1.70GHz (8 cores)
- Memory: DDR4-2666 ECC 16GB * 4 (total 64GB)
- Network card: SOLARFLARE X2522-PLUS XtremeScale 2-Port10/25GbE SFP28 PLUS (configured in 25 Gb/s)
Data on the client (for the source file) and the server were stored on a Samsung SSD 860 EVO 1 TB.
Getting our butt kicked
After running the first round of benchmarks, we could see that we were doing well, except for one outsider
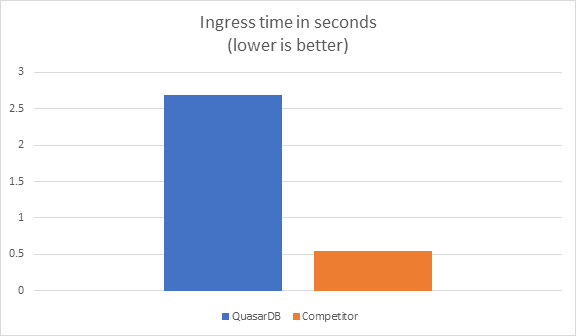
Ah! Well, I guess we can forget about being a high performance timeseries database, time for a pivot? This competitor is five times faster than us!
Interpreting results
If you remember our previous blog post about performance, there is a section where we discuss that a significant performance difference needs a very solid explanation.
In this case, the two databases have been running on the same hardware in a controlled environment. A 5X factor is statistically significant and was reproduced every time.
The QuasarDB core is the result of 10 years of intense R&D centered about database performance. It is written in Modern C++ 17, we have high-performance compression algorithms, bypass the kernel to write to disk thanks to Helium, have zero-copy network protocol and have high performance, column-oriented representation of the data.
When using railgun, data is sent in optimal packet and data is barely transformed, if not at all.
Is our hubris blinding us? Is there something we are missing; an obvious optimization or performance gain we’re not aware of?
A first adjustment
Upon careful inspection, it seemed one parameter eluded us. The competitor was doing a multithreaded insertion of the CSV file, while we were doing a single threaded insertion.
It then became obvious that, yes, of course, the competitor could insert much faster than us using multithreading. We thus adjusted their importing tool to use a single thread, but they were still significantly ahead.
A second adjustment
This is the moment to discuss about the number one trick used by databases to cheat insertion benchmarks: buffered writes.
While writes are rarely completely unbuffered, in our case none of the 100 MiB were written to disk.
Database vendors may make the asynchronous nature of the persistence not so obvious and in a benchmark, the temptation is great to omit this “detail”. You can very easily be the number one database by using asynchronous insertion and have everyone else set to synchronous insertion. Or just use a buffer a bit larger than everyone else…
Asynchronous persistence has its raison d’être and is not “evil” by any measure, it just comes with a heavy price: when the buffer is full, writes are stalled. Or if the database allows the buffer to grow indefinitely, it will eventually run out of memory (Couchbase is famous for that limitation).
One way to beat buffered writes, if it cannot be disabled, is thus to insert data larger than the buffer. In future benchmarks, we’ll show you how database behave when you insert more than 110 MiB. It’s also interesting as it stresses automatic compaction and trimming processes (if any).
In this very instance, solving this problem was easy as the competitor was no one else but… ourselves! Indeed, for the sake of the demonstration, and because we have no interest in shaming a competitor, we simply set railgun to asynchronous mode.
We hope this example will have taught you how to second guess the benchmarks you’re being shown.
Gentlemen, start your engine!
Be not disappointed dear reader, you came here to see us crush the competition in benchmarks and crush the competition we shall!
One notable absence: because of the KDB+ license, we cannot include KDB+ in these results. You can however, do the tests yourselves with our free community edition!
The TSDB compared are thus:
- QuasarDB 3.2.0
- ClickHouse 19.4.1.3
- TimescaleDB 1.2.2 using PostgreSQL 11.2
- InfluxDB 1.7.5
Notes
QuasarDB
Insertion was doing our importer tool called “railgun”. We did the insertion using synchronous commits with one and two threads (for a fair comparison with ClickHouse).
QuasarDB was configured using Helium and the disk was mounted as a raw device, enabling kernel bypass. Import was done with our importer tool, “railgun”.
ClickHouse
We inserted data using the “CSV INSERT” query.
Even when configuring the inserter to be single threaded, it seems to use two threads according to system monitoring tools. This may be a bug or a design limitation. We included values for QuasarDB with 2 threads for this reason.
InfluxDB
For insertion, we wrote a custom Go script using the insertion API. We tried using Telegraph, it was much slower. We also tried converting the CSV and then using the influx import function, and it was slower. We would be keen on knowing if there is a faster and more efficient way to insert into InfluxDB has it delivered the worse results of the benchmarks.
TimescaleDB
We used “COPY FROM” to insert the CSV file.
The results
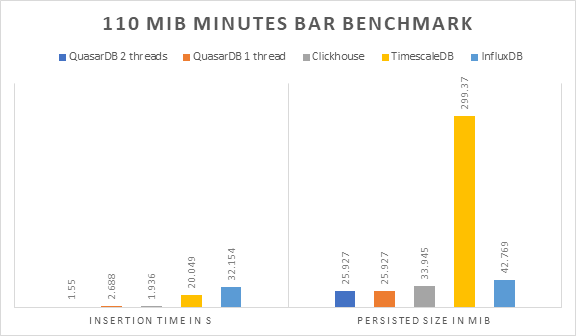
Our benchmark shows that QuasarDB outperforms every database in both speed and size. ClickHouse comes as second for speed and disk usage.
It must be noted that QuasarDB offers the best performance while delivering a different level of reliability, as when the device is mounted raw with Helium, the data is only buffered for one page and data is physically persisted to disk, bypassing all system caches.
Additionally, QuasarDB engine is transactional, ensuring consistency of the inserted data.
Neither TimescaleDB nor InfluxDB managed to deliver satisfactory insertion performance (If you believe we used the wrong approach for either database, feel free to reach out).
For disk usage, QuasarDB is number one and we’re currently working on significant compression improvements for 3.3, we thus expect our advance to grow. Should we then rename the database to PiedPiperDB?
In all fairness, all timeseries databases except TimescaleDB did well on the disk usage part. TimescaleDB uses more than ten (10) times the disk the best performer did. This is problematic as timeseries use cases are typically voluminous.
If we show the ranked results with percentages, we have:
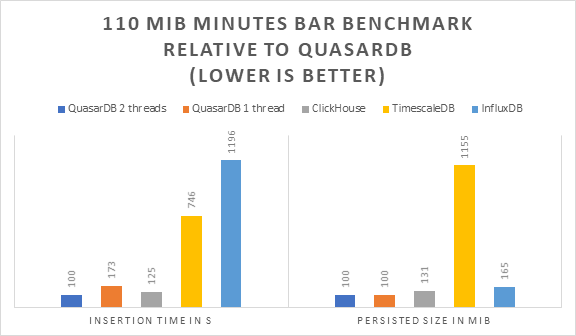
If we aggregate the results, the ranking for ingress performance for this test is:
- QuasarDB
- Clickhouse – 128 % (w.r.t QuasarDB 2 threads)
- InfluxDB – 680 % (w.r.t QuasarDB 1 thread)
- TimescaleDB – 950 % (w.r.t QuasarDB 1 thread)
We hope you enjoyed this performance report, stay tuned as we’re going to stress the database ingress capabilities even more in a future post! We will see that larger workloads increase the performance difference between the various engines.
In the meantime, why don’t you give QuasarDB a try?