Here comes the AI train, next stop is you
It seems a law has been passed that makes it mandatory to mention AI in every business conversation, replacing the law that made the words “blockchain”, “metaverse”, or “synergy” mandatory.
In other words, the hype for AI couldn’t be stronger, but, as with the late 90s hype around the Internet, a massive change is underway.
In this article, we’ll discuss how AI is changing expectations for data management and performance, based on our experience working with customers. When Quasar started, we were focused on a very niche problem of market data management. Now, all our discussions are about “I need AI to access everything immediately”.
A clarification: this article is not about the specific database needs of large language models (LLMs). I’m not talking about vector search, embeddings, model training, token storage, retrieval-augmented generation, or whatever new acronym was invented between the moment I started writing this sentence and the moment you finished reading it.
The point is broader: AI has changed what users expect from data systems. Once people get used to asking a system a question in plain English and receiving an answer in seconds, they start asking why the rest of their data infrastructure cannot behave the same way. Why can’t I query all my sensor data? Why can’t I ask questions across years of market data? Why does the report need to be prepared in advance? Why do I need to know which table contains the answer? Why does this dashboard only answer the five questions someone anticipated six months ago?
These are reasonable questions.
Unfortunately, they are also the kind of reasonable questions that expose every shortcut, assumption, and architectural tradeoff in a database system.
The old contract
For a long time, databases benefited from an implicit contract with their users. The database stored the data, indexed some of it, exposed query capabilities, and returned answers within acceptable timeframes. In exchange, users asked questions the system was prepared to answer.
This contract was everywhere. Transactional systems were expected to support indexed lookups and small updates. Analytical systems expected modeled data, batch loading, pre-aggregation, and queries written by people who knew enough SQL to be dangerous. Dashboards are expected to have a fixed set of filters, dimensions, and charts. Time-series systems are expected to handle time-bounded queries, known series, and predictable aggregation patterns. If a question became common, someone optimized it. If a query became slow, someone added an index, a materialized view, or a pipeline. If the system could not answer a question, the question quietly became “out of scope”, which is a polite way of saying “please don’t do that”.
This was not a failure. This is how serious systems get built. You cannot make everything fast, exact, fresh, flexible, and cheap at the same time. So, you design around expected workloads. You choose storage layouts, indexes, compression schemes, partitioning strategies, consistency guarantees, and execution models based on what you believe users will do.
The problem is that AI interfaces make users less willing to respect those boundaries. A chat box does not expose the database schema. It does not reveal the partitioning strategy. It does not warn the user that their question implies a full historical scan, a high-cardinality group-by, and a join across three systems held together by a shell script written in 2017. It simply invites the user to ask.
“We have the data” is not enough
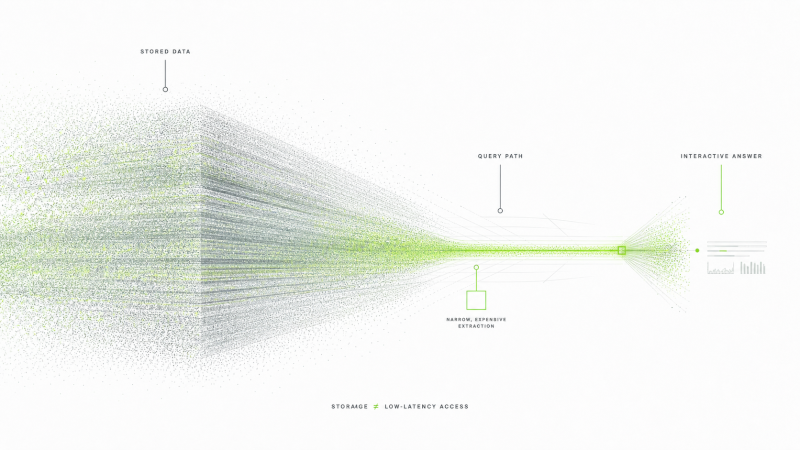 A common source of confusion is the difference between storing data and querying data. Many systems can store large volumes of data. Far fewer can answer arbitrary questions over that data with low latency, high concurrency, and reasonable cost. This distinction sounds obvious to database people, but it is not obvious to users, and it is often blurred by vendors.
A common source of confusion is the difference between storing data and querying data. Many systems can store large volumes of data. Far fewer can answer arbitrary questions over that data with low latency, high concurrency, and reasonable cost. This distinction sounds obvious to database people, but it is not obvious to users, and it is often blurred by vendors.
When a system is advertised as “scalable”, users often hear, “I can keep adding data and the system will keep working the way it did during the demo.”
When a system is advertised as “scalable”, users often hear, “I can keep adding data and the system will keep working the way it did during the demo.” What the vendor may mean is more limited: the system can ingest a lot of data, or store a lot of data, or answer a particular benchmark query over a large dataset, or perform well if the data is partitioned correctly, the query shape is friendly, the working set fits in memory, the cardinality stays reasonable, and the moon is in the correct phase.
This gap creates surprise. A customer adds more data and expects the system to degrade gracefully. Instead, queries become slow, dashboards time out, costs increase sharply, or the system works for the common case but collapses when users ask a slightly different question. Nobody necessarily lied. The system may do exactly what it was designed to do. The problem is that “handles large datasets” is not a complete specification.
Scale has dimensions. Data volume is only one of them. Freshness matters. Query shape matters. Cardinality matters. Compression matters. Concurrency matters. Hot and cold storage matter. The ratio between reads and writes matters. The selectivity of filters matters. The distribution of data matters. A database can scale beautifully along one axis and poorly along another. This is why benchmark numbers often tell you less than you think, and why “petabyte-scale” should always be followed by “doing what, exactly?”
Real-time means several different things
The word “real-time” also causes trouble, because people use it to mean different things. For some systems, real-time means the data arrives quickly. For others, it means alerts fire quickly when a known condition occurs. For dashboards, it may mean the chart refreshes every few seconds. For users influenced by AI interfaces, it increasingly means something stronger: I can ask a new question over the latest data and get an answer now.
Ingesting data quickly does not mean arbitrary queries will run quickly.
These are different engineering problems. Ingesting data quickly does not mean arbitrary queries will run quickly. Refreshing a dashboard quickly does not mean the raw data is queryable at interactive latency. Triggering an alert quickly does not mean the system can support exploratory analysis. A dashboard can feel real-time because someone has already decided which questions it will answer and precomputed enough state to answer them cheaply.
This distinction matters more now because AI changes the shape of interaction. A user does not only want the current value of a metric. They want to ask a follow-up question. Then another one. They want to compare this week to last year, exclude a category, group by a field no one indexed, correlate two signals, and ask why a subset behaves differently. The first answer creates the next question. This is where systems designed around fixed dashboards start to struggle.
Precomputation does not disappear
Much of what people call analytics is really precomputation with a user interface on top. This is not an insult. Precomputation is one of the best tools we have. If many users repeatedly ask the same question, you should not recompute the answer each time. If a business needs monthly revenue by region, you probably want a prepared table, not a heroic scan of raw events every time someone opens a browser.
The issue is that precomputation works best when you know the questions in advance. AI-driven interfaces weaken that assumption. Users can ask questions that no one has modeled, indexed, or placed on a dashboard. Some of those questions will be silly, but many will be valuable. In industrial, financial, energy, and observability data, the most interesting questions are often the ones you ask after seeing the first result.
This does not mean every question should hit raw data. That would be naïve and expensive, which is a bad combination unless you are selling cloud credits. Good systems still need summaries, downsampling, sketches, caches, materialized views, tiered storage, and workload isolation. What changes is that these mechanisms must support more exploration. The system has to guide the user through tradeoffs instead of pretending every answer can be exact, fresh, cheap, and instantaneous.
AI exposes database limits
 AI does not remove the database problem. It makes the question easier to ask, but the system still has to answer it. The model can generate SQL, choose tools, or orchestrate a workflow, but somewhere underneath, machines still need to read blocks, decompress data, evaluate predicates, join tables, aggregate values, sort results, enforce permissions, and move bytes across networks.
AI does not remove the database problem. It makes the question easier to ask, but the system still has to answer it. The model can generate SQL, choose tools, or orchestrate a workflow, but somewhere underneath, machines still need to read blocks, decompress data, evaluate predicates, join tables, aggregate values, sort results, enforce permissions, and move bytes across networks.
AI makes the workload harder precisely because it reduces the cost of asking questions.
In some cases, AI makes the workload harder precisely because it reduces the cost of asking questions. When only analysts can write SQL, only analysts generate dangerous queries. When everyone can ask questions in natural language, the potential query surface expands. The database now serves more users, more exploratory workflows, and more poorly anticipated access patterns.
This is why many systems suddenly look worse in the AI era, even though the systems themselves did not change. The workload changed. More precisely, expectations changed. A system designed for scheduled reporting now faces interactive exploration. A system designed for known dashboards now faces generated queries. A system designed for a small number of trained users now faces a much larger audience. The old assumptions no longer hold.
What should improve
The answer is not to sprinkle AI on top of a database and hope for mercy. The answer is still database engineering, which is less fashionable but more effective. Systems need better storage layouts, indexing strategies, compression, query planning, memory use, workload isolation, and handling of high-cardinality data. They also need to communicate tradeoffs more honestly.
High cardinality deserves special attention. Many real-world datasets are not clean benchmark tables. They contain millions of sensors, tags, instruments, customers, devices, symbols, or assets. They combine dense and sparse signals. They contain historical data that users still expect to query. They receive fresh data while users analyze old data. In these environments, “just add an index” or “just use a warehouse” often stops being a serious answer.
What users cannot work with is a system that feels fast until it randomly stops being fast. Interactive analytics requires latency that users can reason about.
Predictability matters as much as raw speed. Users can accept that some queries are approximate, some touch cold data, some cost more, and some need more time. What they cannot work with is a system that feels fast until it randomly stops being fast. Interactive analytics requires latency that users can reason about. If the system must sample, say so. If the query touches cold storage, say so. If the answer will be approximate, say so. Hiding the tradeoff does not make it disappear; it only moves the surprise to production.
Parting words
AI has not created a new desire for fast answers. People always wanted fast answers. What changed is that AI made broad, natural language interaction feel normal. Once users experience that, the old model of static dashboards, prepared reports, and carefully constrained queries starts to feel insufficient.
This will put pressure on database systems, especially systems that manage large numerical, time-series, industrial, financial, or operational datasets. Users will expect fresher data, lower latency, higher concurrency, and more freedom to explore. They will not always understand why storing and querying data are different problems. That misunderstanding will create frustration, but it will also create demand for better systems.
The winning systems will not be those that claim all trade-offs have disappeared. They have not. The winning systems will be the ones that make large datasets queryable with predictable performance, expose the cost of different choices, and support exploration without requiring every useful question to be predicted in advance.
AI is opening the gates to more users and more questions. The infrastructure behind them needs to be ready.
Curious about how we approach this problem at Quasar? Read on!


